用反思机制构建会自我纠错的 AI Agent
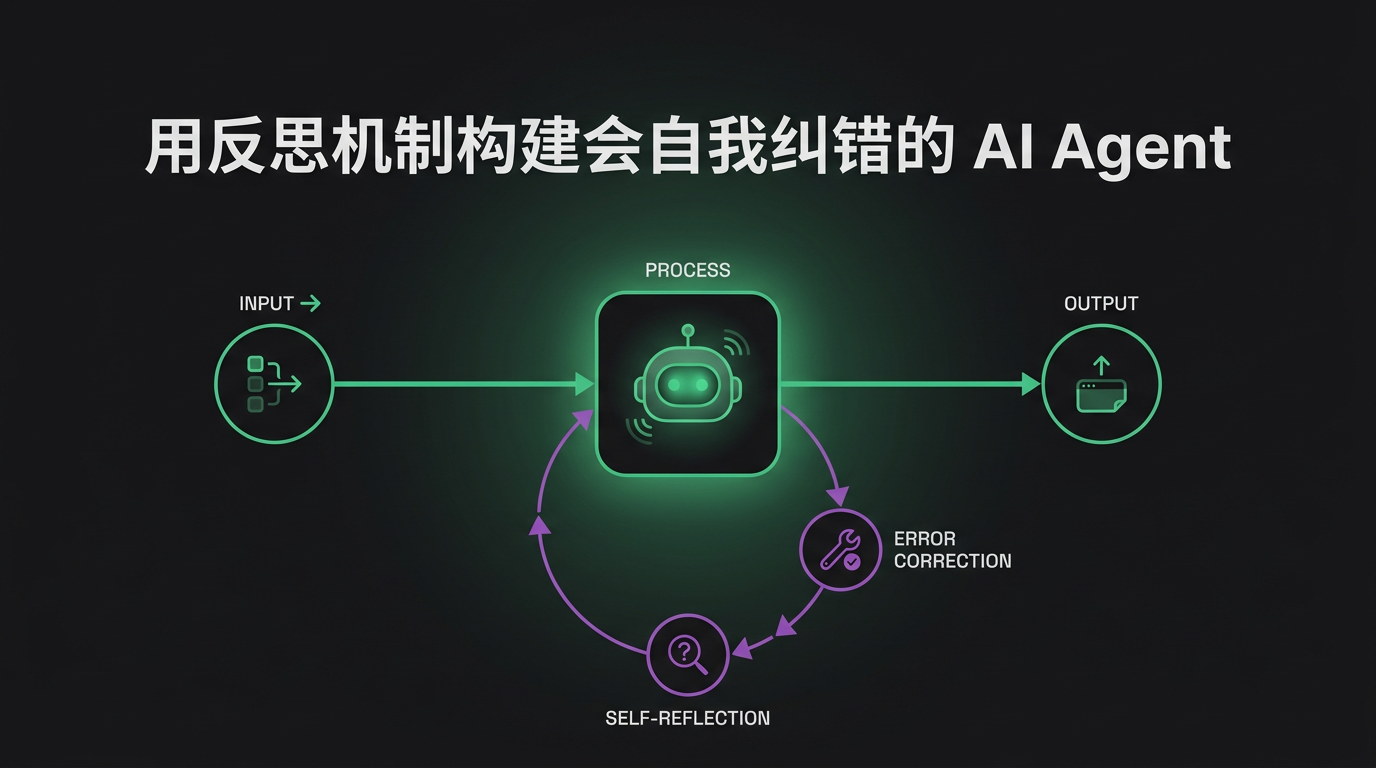
如何用反思模式和持久记忆构建会自我纠错的 AI Agent。一个可运行的 Python 循环,Agent 批判自己的输出、修正错误并记住它们。
TL;DR — 自我纠错 Agent 比普通 Agent 多两样东西:一个反思步骤(提交前批判自己的输出),以及一份过往错误的记忆(不再重复犯)。反思在任务内抓错误;记忆跨任务防错误。本文用纯 Python 把两者都搭出来——不需要框架——并指出每个到底在哪有用、在哪只是烧 token。
“自我纠错”到底是什么意思
这词被随便用。具体说,自我纠错 Agent 做两件不同的事:
- 反思(任务内): 在敲定答案前,Agent 对照目标审查自己的草稿、找出缺陷、修订。这抓的是单个任务内的错误。这个技术在 Self-Refine 和 Reflexion 论文里有正式表述。
- 失败记忆(任务间): 当 Agent 搞错了并学到修法,它记下这个教训,在未来任务里回忆它。这防的是跨任务重复同一个错误。
它们解决不同问题。大多数”自我纠错 Agent”教程只做反思就收工了。记忆那一半才是真正让 Agent 随时间进步的东西。存储那一面我们在 Agent 记忆架构讲过;这里把它接进一个纠错循环。
反思循环
核心模式是 生成 → 批判 → 修订。这是一个能跑的最小版本。
from openai import OpenAI
client = OpenAI(base_url="https://api.sandbase.ai/v1", api_key="sk-...")
MODEL = "anthropic/claude-sonnet-4"
def generate(task: str, prior_feedback: str = "") -> str:
prompt = task
if prior_feedback:
prompt += f"\n\nA previous attempt had this problem:\n{prior_feedback}\nFix it."
resp = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
)
return resp.choices[0].message.content
def critique(task: str, draft: str) -> tuple[bool, str]:
"""返回 (is_good, feedback)。Agent 评判自己的工作。"""
prompt = (
f"Task: {task}\n\nDraft answer:\n{draft}\n\n"
"Critique this draft. If it fully satisfies the task, reply exactly 'PASS'. "
"Otherwise, list the specific problems to fix."
)
resp = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
)
feedback = resp.choices[0].message.content.strip()
return feedback == "PASS", feedback
def solve(task: str, max_iterations: int = 3) -> str:
feedback = ""
for i in range(max_iterations):
draft = generate(task, feedback)
ok, feedback = critique(task, draft)
if ok:
return draft
return draft # 达到最大迭代后返回尽力而为的版本结构比 prompt 更重要。从生产里跑出来的三条规则:
给迭代设上限。 没有 max_iterations,挑剔的批判者会永远循环。三次通常够;超过三次你在以全额 token 成本打磨递减收益。
批判者需要目标,不只是草稿。 只看草稿的批判步骤会臆造问题。把原始任务给它,让它对照真实需求评判。
让 PASS 是一个精确 token。 模糊的”看着不错!“很难解析。强制一个字面的 PASS,让你的控制流确定。
反思何时有用、何时没用
反思不免费——它至少让你的 token 成本和延迟翻倍。它的回报不均匀:
| 任务类型 | 反思有用吗? | 为什么 |
|---|---|---|
| 代码生成 | 强有用 | 批判者抓 bug、漏掉的边界情况 |
| 数学/逻辑 | 强有用 | 自检发现算术和推理的滑误 |
| 结构化抽取 | 中等 | 抓 schema 违规、漏字段 |
| 创意写作 | 弱 | ”更好”是主观的;批判者加不了多少 |
| 简单查询 | 没用 | 没什么可反思的;纯浪费 |
教训:用任务类型给反思设门。别每次调用都反思。琐碎的分类不需要自我批判;代码生成步骤需要。这跟把可靠、低成本的 Agent 和烧钱的区分开来的选择性花费纪律是同一个。
加记忆:跨任务学习
反思修当前任务。它对下一个任务毫无作用。如果 Agent 一直犯同一个错(日期格式错、忘了校验输入、读错 API),反思每一次都重新发现并重新修。那很浪费。
解法:当批判者发现一个真实问题,存下教训。未来任务里把相关教训加载进 prompt。
import json
from pathlib import Path
LESSONS_FILE = Path("lessons.json")
def load_lessons() -> list[str]:
if LESSONS_FILE.exists():
return json.loads(LESSONS_FILE.read_text())
return []
def save_lesson(lesson: str):
lessons = load_lessons()
if lesson not in lessons:
lessons.append(lesson)
LESSONS_FILE.write_text(json.dumps(lessons, indent=2))
def extract_lesson(task: str, feedback: str) -> str:
"""把一个具体批判变成可复用规则。"""
prompt = (
f"A task had this problem: {feedback}\n"
"Write one short, general rule (one sentence) to avoid this in future tasks."
)
resp = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
)
return resp.choices[0].message.content.strip()
def solve_with_memory(task: str, max_iterations: int = 3) -> str:
lessons = load_lessons()
lesson_text = "\n".join(f"- {l}" for l in lessons)
augmented_task = task
if lesson_text:
augmented_task = f"{task}\n\nLessons from past tasks:\n{lesson_text}"
feedback = ""
for i in range(max_iterations):
draft = generate(augmented_task, feedback)
ok, feedback = critique(task, draft)
if ok:
return draft
# 持久化教训,让未来任务受益
save_lesson(extract_lesson(task, feedback))
return draft关键变换在 extract_lesson:它把一个具体批判(“你用了 MM/DD/YYYY 但 API 要 ISO 8601”)变成一个通用规则(“API 调用永远用 ISO 8601 日期格式”)。具体反馈不可迁移;通用规则可以。
这是个刻意简单的记忆:一个加载进每个 prompt 的扁平 JSON 列表。它能用到教训列表增长超过上下文能舒服容纳的量,那时你切到检索——给教训做 embedding,每个任务只取相关的。那就是温-冷记忆划分的实战。
老实说的取舍
自我纠错不是免费升级。代价:
- Token 乘数。 反思大约让每个任务的 token 翻 2-3 倍。记忆加一个更小的恒定开销(加载教训)。
- 延迟。 每次反思迭代是又一个往返。3 迭代循环能让墙钟时间翻三倍。
- 批判者会出错。 有缺陷的批判者拒绝好答案或批准坏答案。你的纠错只跟你的批判步骤一样好。
- 教训污染。 坏教训会堆积。一个过度通用的规则(“永远复查一切”)加噪音不加价值。修剪教训库。
从中获益的团队不会到处用它。他们把反思用在高风险、易错的步骤(代码、结构化输出、多步计划),让便宜、低风险的调用只跑一次。
FAQ
反思跟 chain-of-thought 一样吗?
不。Chain-of-thought 是答案之前的推理,在一次里。反思是批判一个已完成的答案并修订它,跨多次。你能组合它们——一步步推理,然后对结果反思——但它们是不同技术。
批判者该用跟生成器一样的模型吗?
通常是,但用不同模型当批判者能抓到生成器看不见的错误。一个实用模式是用强模型生成、用同一个或更便宜的批判。批判者的活(找缺陷)有时比生成器的活(产生正确答案)更容易。
怎么阻止 Agent 永远循环?
硬上限迭代(3 是好默认),到上限就返回最佳尝试。自我批判者总能找到某些可改进的,所以无界循环永不终止。上限不可商量。
生产环境教训该存哪?
从 JSON 文件或每用户/Agent 一行数据库起步。一旦教训超过上下文能容纳的量,移到向量库,每任务只取相关教训。检索设计见 Agent 记忆架构。
这适用任何模型吗?
适用。这个模式与模型无关——只是结构化 prompt 加一个控制循环。更强的模型产生更好的批判、需要更少迭代。通过 OpenAI 兼容网关你能换模型不改循环。
关键要点
- 自我纠错有两部分:反思修任务内的错误,记忆防跨任务重复。大多数教程跳过了记忆那一半。
- 反思循环是 生成 → 批判 → 修订,带硬迭代上限,批判者要看到原始目标而不只是草稿。
- 用任务类型给反思设门。它强烈帮助代码和逻辑,对简单查询毫无用处,大约让 token 成本翻 2-3 倍。
- 记忆靠把具体批判转成通用规则起作用。从 JSON 列表起步,超出上下文窗口时移到检索。