Agent 记忆架构对比:向量 vs 图谱 vs 情景记忆(2026)
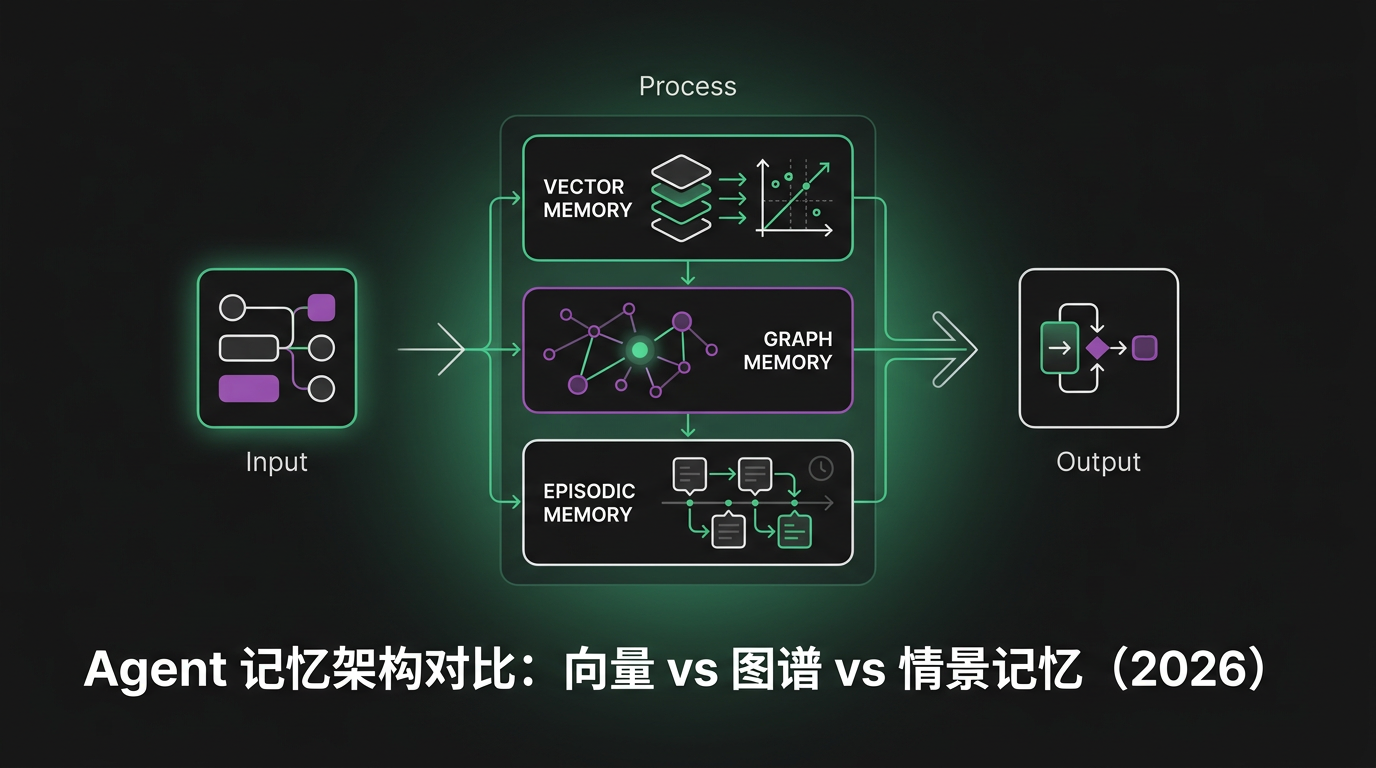
对比 2026 年三种 Agent 记忆架构——向量召回、知识图谱、情景缓冲——附真实延迟数据、失败模式和选型决策指南。
TL;DR — 向量记忆快且便宜,但丢失关系。图谱记忆能抓住结构,但每次查询多 200-400ms。情景缓冲保留时间顺序,但吃爆你的 context window。2026 年的生产级 Agent 三层全用。下面讲怎么把它们接在一起。
那个没人提前告诉你的问题
你搭了一个 Agent,Demo 跑得特别好。然后用户问了一句三个 session 前提过的事,Agent 一脸茫然,好像你们从没见过。
这不是 prompt 工程的锅。选择 Agent 记忆架构是大多数团队都会搞错的底层设计决策:大多数 Agent 框架把记忆当成附属品——挂一个向量库,剩下的交给运气。但到了 2026 年,“有记忆的 Agent”和”记忆力真的好的 Agent”之间的差距,已经成了玩具和生产系统之间的核心区别。
过去几个月我在不同框架(Hermes、OpenClaw、LangGraph、自研)上搞记忆系统。下面是真正有效的方案、默默失败的陷阱、以及 Anthropic 五月份发布 “Dreaming” 之后这个领域的走向。(想对比 Hermes 和 OpenClaw 这两个框架,可以看我们的 Hermes Agent vs OpenClaw 对比。)
三种记忆架构,三种死法
1. 向量记忆(语义召回)
最常见的模式。把对话或提取的事实做 embedding,存到向量库(Pinecone、Qdrant、Weaviate、pgvector),查询时用余弦相似度检索。
实际工作方式:
from openai import OpenAI
client = OpenAI(base_url="https://api.sandbase.ai/v1", api_key="...")
def store_memory(text: str, metadata: dict):
embedding = client.embeddings.create(
model="openai/text-embedding-3-small",
input=text
).data[0].embedding
vector_db.upsert(id=uuid4(), vector=embedding, metadata=metadata, text=text)
def recall(query: str, top_k: int = 5):
q_embedding = client.embeddings.create(
model="openai/text-embedding-3-small",
input=query
).data[0].embedding
return vector_db.query(vector=q_embedding, top_k=top_k)优势: 偏近期的语义召回。“我们之前聊的认证方案是什么?”—— 秒找到相关片段。托管服务上 top-5 查询通常 50-150ms。
踩坑记录:
- 多跳推理直接挂。 “John 推荐的那个库、就是 Sarah 那个项目用的那个叫啥?“——需要连接三个实体。向量相似度把每条事实当孤岛,没有关系结构。
- 时间混淆。 用户一月说”我搬到柏林了”,三月说”我搬到东京了”。向量召回可能把柏林那条捞出来,因为 embedding 碰巧更接近当前查询。没有内建的”后者覆盖前者”逻辑。
- 规模退化。 最近有个数学证明指出:embedding 检索的几何特性在小规模下让它好用,在大规模下迫使它遗忘。记忆越多,召回越差。
真实数据: Mem0 在大规模记忆场景下报告 7-10 秒响应时间。不是检索延迟——是包含抽取、去重、重排的完整管线。
2. 图谱记忆(结构召回)
不嵌入平文本,而是提取实体和关系放进知识图谱。Zep 的 Temporal Knowledge Graph 是最成熟的实现;Mem0 在 2026 年初加了图谱层。
核心思路:
用户 → [就职于] → Acme 公司
用户 → [偏好] → Python
用户 → [部署到] → AWS us-east-1
Acme 公司 → [使用] → KubernetesAgent 需要回答”我公司用什么基础设施?“时,沿图遍历:用户 → 就职于 → Acme → 使用 → Kubernetes。纯向量相似度做不到这种多跳推理。
优势:
- 关系查询(“谁介绍我用的这个工具?”)
- 偏好一致性(“永远用 TypeScript” 即使过了 50 个 session 也不会丢)
- 矛盾检测(新事实通过时间边显式覆盖旧事实)
踩坑记录:
- 提取贵且有损。 把自然语言变成结构化三元组需要每轮对话一次 LLM 调用。多 200-400ms 延迟,烧掉 500-2000 token 在提取上。
- Schema 刚性。 要么预定义实体类型(限制能捕获什么),要么让 LLM 自己决定(引入不一致——“Python” 还是 “python” 还是 “Python 3.12”?)。
- 冷启动。 图谱记忆在填充前没用。前 5-10 个 session 感觉跟无状态 Agent 没区别。
真实数据: Zep 生产环境图谱查询平均 4 秒延迟。Mem0 的混合方案(向量+图谱)宣称比纯向量快 91%,但他们的 benchmark 场景是偏好召回。
3. 情景记忆(时间缓冲)
最接近人类记忆的模式——完整的事件片段(整个 session 或任务序列)按时间存储,逐步压缩总结,以叙事而非孤立事实的形式检索。
Anthropic 的 “Dreaming”(2026 年 5 月 6 日发布)是最高调的实现。在活跃 session 之间,Claude Agent 回顾过去的工作、提取模式、发现反复出现的错误、改写自己的记忆。Harvey(法律 AI 公司)启用后报告 Agent 任务完成率提升了 6 倍。
模式:
Session 1(完整记录)→ [总结] → Episode 1(压缩版)
Session 2(完整记录)→ [总结] → Episode 2(压缩版)
...
Episode 1-10 → [整合] → Meta-episode(更高层的模式)优势:
- 时间顺序保留。“上次我们试了 X 失败了,所以这次…”
- 叙事连贯。Agent 能解释自己的历史和学习过程。
- 自我进化。从 episode 回顾中浮现单条事实无法显现的模式。
踩坑记录:
- Context window 膨胀。 即使压缩过的 episode 也吃 token。加载 20 个 session 摘要 × 200 token = 4000 token 的前置开销,还没开始当前任务。
- 总结损耗。 每次压缩都丢细节。Session 7 的那条精确报错信息可能正好是 Session 15 需要的,但已经被总结掉了。
- 整合成本。 Anthropic 的 Dreaming 作为后台进程运行——本质上每个 session 多一次 LLM 调用,你付钱但用户看不见。
2026 生产模式:分层记忆
没有人只用一种记忆了。主流架构长这样:
| 层级 | 存储 | 检索延迟 | 用途 |
|---|---|---|---|
| 热(短期) | Context window 内 | 0ms(已加载) | 当前会话状态 |
| 温(中期) | Markdown 文件或 KV 存储 | 10-50ms | 用户画像、偏好、活跃项目上下文 |
| 冷(长期) | 向量库 + 图谱 + 情景日志 | 100-500ms | 历史召回、关系查询、模式检测 |
每轮的流程:
- 加载热上下文(当前对话 + 系统 prompt)
- 加载温上下文(user.md、项目笔记——始终包含,~500-1000 token)
- 如果查询需要历史上下文 → 路由到冷层
- 冷层并行查询:向量相似度 + 图谱遍历 + 情景搜索
- 记忆路由器(轻量 LLM 调用或分类器)筛选哪些结果相关
- 注入选中的记忆到 context,生成回复
- 回复后:为图谱提取事实、为向量库做 embedding、追加到 episode 日志
关键洞察:温记忆始终加载,冷记忆按需检索。 这样保持基础延迟低,同时在需要时有深度召回能力。
# Hermes 风格的记忆配置
memory:
warm:
- user.md # 始终加载。关于用户的事实。
- project.md # 当前项目上下文。按工作区切换。
cold:
vector_store: qdrant
graph_store: neo4j # 可选,增加关系查询能力
episode_log: sqlite # 压缩的 session 摘要
consolidation:
schedule: "0 3 * * *" # 每夜整合(类似 Dreaming)
model: anthropic/claude-sonnet-4 # 后台任务用便宜模型选型决策框架
别想”我该用哪个”,想”我该先建哪个”。
先搞温层 Markdown 文件,如果:
- Agent 服务一个用户或小团队
- 记忆需求主要是偏好和项目上下文
- 你想要零基础设施开销
- 你接受手动维护(用户自己编辑记忆文件)
加向量记忆,当:
- 对话历史超过 context 能装的量(~50+ session)
- 用户经常问”我们之前讨论 X 的时候说了啥?”
- 你需要模糊匹配(“好像是关于部署的… 可能是 kubernetes?”)
- 你能接受 7-10 秒延迟(Mem0)或 4 秒(Zep)
加图谱记忆,当:
- 你的领域有真实关系(人 → 团队 → 项目 → 工具)
- 用户问多跳问题(“Sarah 团队用什么做 CI?”)
- 你需要矛盾解决(新事实覆盖旧事实)
- 你能承受提取成本(每轮 ~500 token)
加情景记忆,当:
- Agent 执行周期性工作流(日报、周报、每日站会)
- 自我进化很重要(Agent 应该越用越好)
- 时间顺序很重要(“我们之前试过 X,不行”)
- 你是为长期关系构建的(月/年级别)
延迟预算的现实
不舒服的事实:每加一层记忆都要付延迟代价。典型预算:
| 操作 | 延迟 | Token 消耗 |
|---|---|---|
| 加载温文件 | 5-10ms | 500-1500 token(始终) |
| 向量检索(top-5) | 50-150ms | 300-800 token |
| 图谱遍历(2 跳) | 200-400ms | 100-400 token |
| 情景检索 | 50-100ms | 200-600 token |
| 记忆路由器决策 | 100-200ms | 100-200 token |
| 完整冷路径 | 400-850ms | 700-2000 token |
这 400-850ms 是加在 LLM 响应时间之上的。对聊天机器人(用户期望 2 秒内响应)来说很紧。对异步编码 Agent(跑几分钟的那种)来说无所谓。
实用优化: 不要每轮都打冷记忆。用轻量分类器(甚至关键词匹配)判断当前查询是否需要历史召回。对话中大多数轮次是跟进问题,只需要热上下文。
接下来的趋势
三件值得关注的事:
-
记忆基础设施在整合。 Mem0、Zep、Letta 是站着的三家。Cloudflare 也入局了 Agent Memory。预计 2-3 家存活,其余合并。
-
整合成为标配。 Anthropic 的 Dreaming 和 Google I/O 2026 的 Memory Bank 之后,“后台记忆处理”不再是稀奇事。年底前每个严肃框架都会有。
-
向量天花板是真的。 那个关于 embedding 几何在规模化下退化的数学证明不会消失。混合架构(向量 + 图谱 + 情景)不是锦上添花——是唯一能在 ~100K 记忆以上保持召回质量的路径。
FAQ
Q:能不能直接用更大的 context window 代替记忆系统?
可以,直到不行为止。Gemini 的 1M token 窗口或 Claude 的 200K 能塞很多历史。但按 $3-15/百万 input token 算,每轮加载 500K token 的历史很快就贵到离谱。记忆系统的价值是加载正确的 2K token,而不是所有 500K token。
Q:Mem0 和 Zep 谁更好?
侧重不同。Mem0 擅长用户偏好召回,向量+图谱混合搜索更好。Zep 的时间知识图谱在多跳关系查询和时间推理上更强。两者完整管线都是 3-10 秒。如果你主要需要”记住用户喜欢什么”,选 Mem0。如果需要”追溯导致这个结果的决策链”,选 Zep。
Q:Anthropic 的 Dreaming 跟 Hermes 的 skill 系统有什么区别?
Dreaming 是被动整合——回顾和策展。Hermes 的 skills 是主动提取——把可复用的流程写成文档。Dreaming 让 Agent 记得更好。Skills 让 Agent 在重复任务上执行更快。两者互补。
Q:生产级 Agent 的最小可行记忆是什么?
一个每次 session 加载的 user.md 文件。认真的。一个 20 行的 Markdown,写着用户的基本信息(“偏好 Python,做电商平台,时区 UTC+8”),对感知智能的提升比一个装满无关噪音的向量库大得多。
Q:怎么测试记忆是否真的有帮助?
跑同一段 10 轮对话两次:一次有记忆,一次没有。用 LLM 当裁判给相关性和连贯性打分。如果记忆没能让分数提升至少 20%,说明你的检索有问题——你在加载噪音,不是信号。