把 MCP Server 接入你的 Agent:实战指南(2026)
2026 年把 MCP Server 接入 AI Agent 的实战指南:传输方式、连接生命周期、真实配置,以及那个烧 token 的 schema 膨胀坑。
TL;DR — MCP(Model Context Protocol)是 Agent 用标准化方式跟工具对话的协议。接入一个 MCP server 三步:选传输方式(本地用 stdio,远程用 Streamable HTTP)、在 Agent 配置里声明 server、让 Agent 发现工具。没人提醒你的坑:冗长的工具 schema 可能比等效的 CLI 多烧 30 倍 token。下面讲怎么做对。
MCP 到底解决什么问题
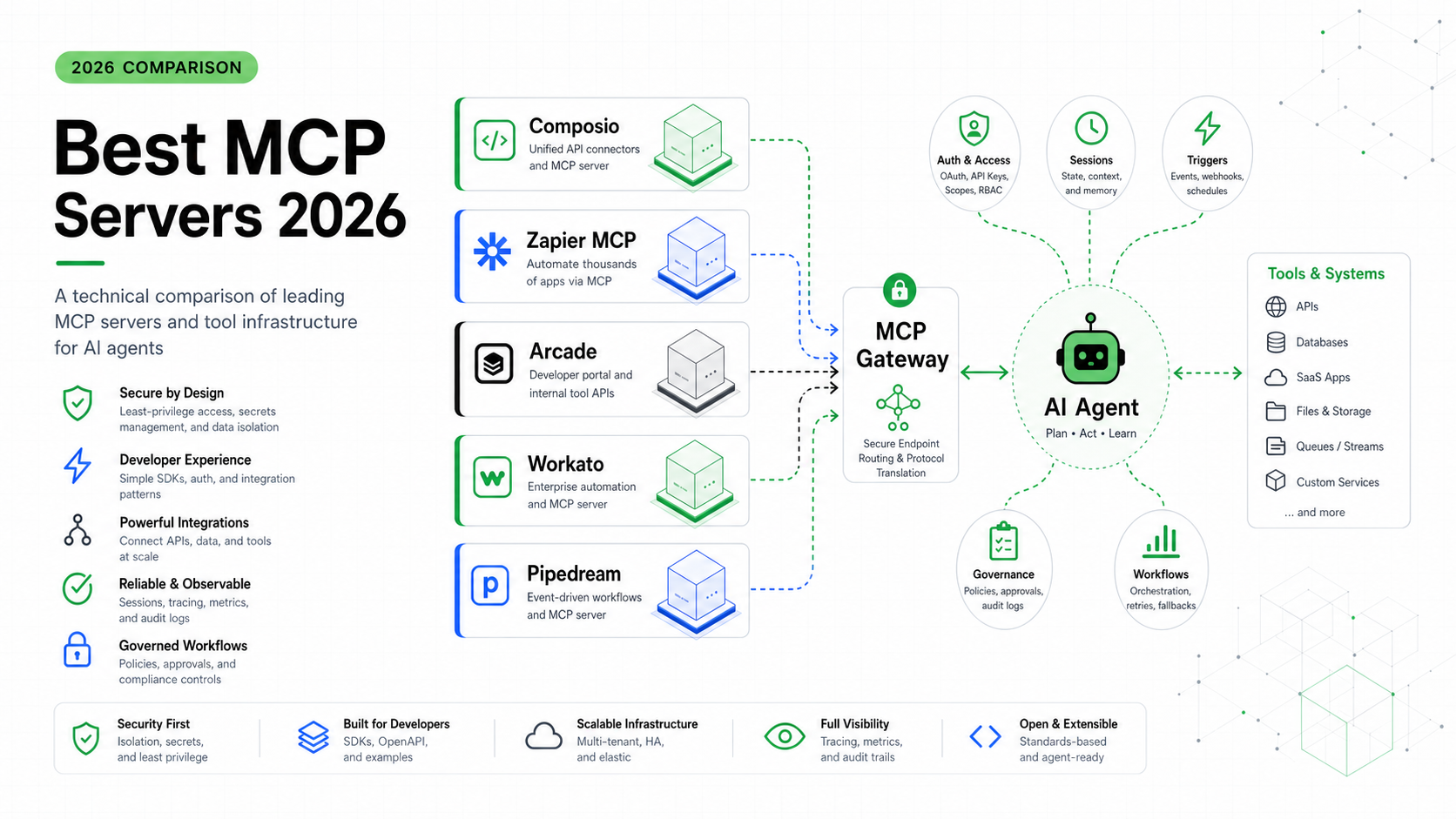
MCP 之前,每个 Agent 框架都有自己定义工具的方式。给 LangChain 写个工具,给 AutoGen 重写一遍,给你的自研 Agent 再重写一遍。把 MCP server 接入 Agent 解决了这个:把工具定义一次成 MCP server,任何兼容 MCP 的 Agent 都能用。它是 Agent 工具的 USB-C——一个标准,多个设备。
2026 年,MCP 从”有意思的 Anthropic 提案”变成了事实标准。Claude Code 有最深的 MCP 集成,但 OpenClaw、Hermes 和大多数严肃框架现在都讲它。如果你在建 Agent,你会接 MCP server。下面是实战机制。
你需要知道的两种传输
MCP 定义 Agent(客户端)和工具 server 怎么通信。有两种重要的传输:
stdio —— 本地 server
server 作为子进程跑在同一台机器上,通过标准输入/输出通信。这是本地工具最简单最常见的设置——文件系统访问、本地数据库、shell 命令。
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/dir"]
}
}
}Agent 启动子进程,通过 stdio 传 JSON-RPC 消息,用完关掉。无网络、无端口、攻击面最小。
Streamable HTTP —— 远程 server
当 MCP server 在别处——共享的团队服务、SaaS 集成、容器化工具——你用 Streamable HTTP。它取代了旧的 HTTP+SSE 传输,是 2026 年远程 MCP 的标准。
{
"mcpServers": {
"company-api": {
"url": "https://mcp.yourcompany.com/mcp",
"headers": {
"Authorization": "Bearer ${MCP_TOKEN}"
}
}
}
}经验法则: 机器上的任何东西用 stdio,跨网络边界的任何东西用 Streamable HTTP。别用蹩脚的 wrapper 把 stdio server 暴露到网络上——用为它设计的传输。
连接生命周期
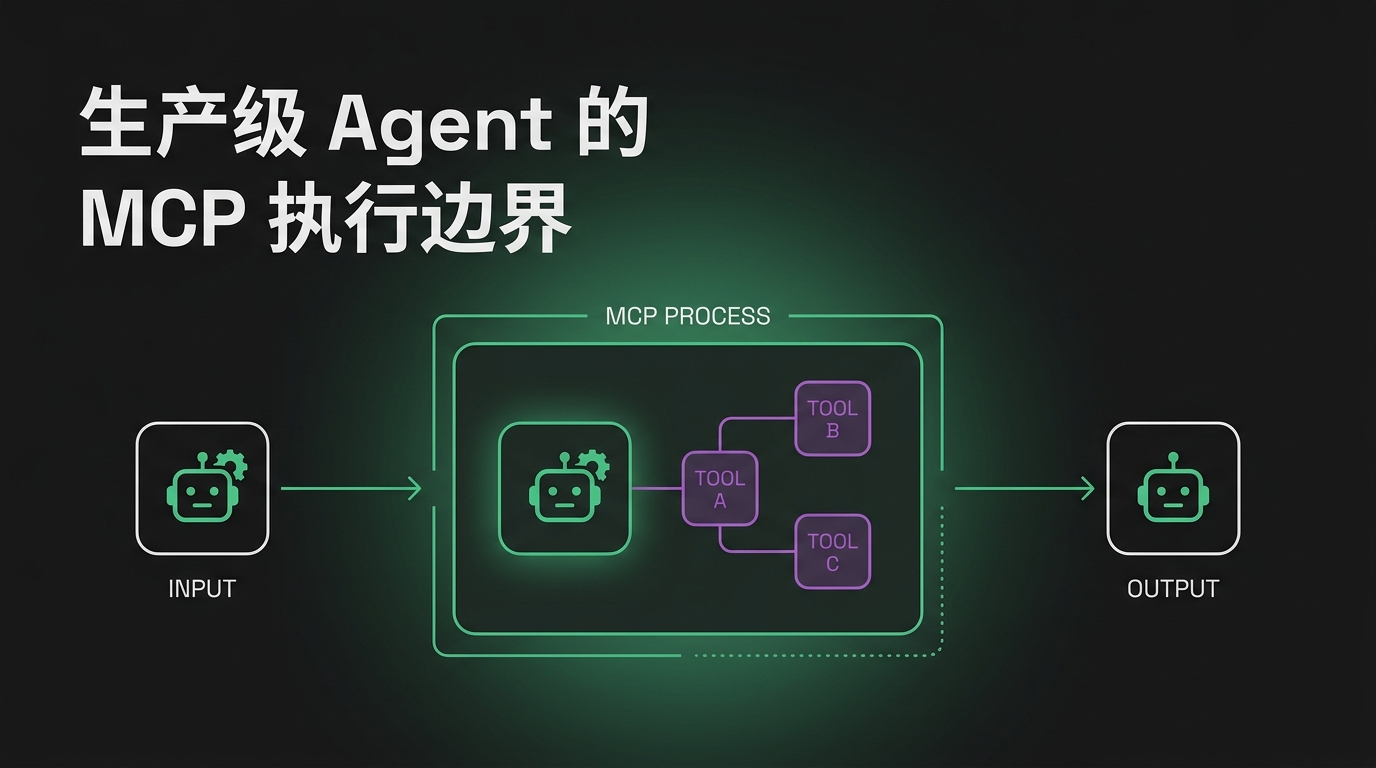
当你的 Agent 连接 MCP server,四件事按顺序发生:
- 初始化 —— 客户端和 server 握手,交换协议版本和能力。
- 发现 —— Agent 问”你有什么工具?” server 返回工具定义,含名称、描述、输入的 JSON Schema。
- 调用 —— 当模型决定用某个工具,Agent 发
tools/call请求带参数。server 执行并返回结果。 - 拆除 —— session 结束时,连接干净关闭(stdio 杀子进程,远程关 HTTP 连接)。
理解发现很关键:server 返回的工具 schema 会注入模型的 context。这很方便——但成本也藏在这。
Schema 膨胀的坑
快速入门里没人写的事:MCP 工具 schema 可能 token 贵得惊人。一个冗长的 MCP server 可能用深度嵌套的 JSON Schema、枚举、每个字段的描述和示例来描述一个工具——而所有这些在每次请求都加载进 context,不管工具用不用。
实践中,设计糟糕的 MCP server 对同样的能力可能比等效 CLI 命令多烧 30 倍 token。如果你接了十个啰嗦的 MCP server,模型还没干任何活就能在工具定义上烧掉几千 token。
真正有用的缓解:
- 只接当前任务需要的 server。 别把整个 MCP 目录加载进每个 session。
- 优先选 schema 精简的 server。 干同样活,5 行 schema 的工具胜过 50 行的。
- 用工具过滤(如果你的框架支持)——只暴露 Agent 需要的特定工具,不是 server 的整个表面。
- 盯紧你的 token 用量。 如果 Agent 的输入 token 莫名其妙地高,先审计你的 MCP 工具定义。
一个完整的连接
下面是把一个文件系统 server 接入 Agent,然后验证工具被发现:
# 大多数框架遵循的连接流程伪代码
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
server_params = StdioServerParameters(
command="npx",
args=["-y", "@modelcontextprotocol/server-filesystem", "/data"]
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
# 发现:列出可用工具
tools = await session.list_tools()
for tool in tools.tools:
print(f"{tool.name}: {tool.description}")
# 调用:调一个工具
result = await session.call_tool(
"read_file",
arguments={"path": "/data/notes.txt"}
)
print(result.content)模型从不看这些管道——它只看到被发现的工具作为可用函数,按名调用。你的活是接好连接、管理哪些 server 处于激活状态。
模型在哪里起作用
MCP server 提供工具;模型决定何时用。这个决策质量高度依赖模型——强模型读懂工具 schema 并正确使用;弱模型误调工具或干脆忽略。
这里路由就有用了。把 Agent 指向 SandBase,让你在工具密集的推理上用强模型、在简单轮次上压成本:
OPENAI_API_BASE=https://api.sandbase.ai/v1
OPENAI_API_KEY=your-sandbase-api-key
MODEL=anthropic/claude-sonnet-4 # MCP 密集工作用强 tool-callingFunction calling 是模型间差异很大的能力,所以一个端点后面有 300+ 模型让你能把模型匹配到任务的工具使用需求。(如果你在选有深度 MCP 支持的编码 Agent,Claude Code 在 MCP 集成上领先。)
FAQ
Q:MCP vs function calling,区别是什么?
Function calling 是模型能力(模型发出调用工具的结构化请求)。MCP 是工具怎么定义、发现、提供的协议。MCP 底层用 function calling,但标准化了工具管道,让工具能跨 Agent 复用。
Q:我需要 MCP,还是直接定义工具就行?
如果你的工具是一次性、单个 Agent 用,直接定义更简单。MCP 在你想让工具跨多个 Agent 复用或团队共享时才值。别为一个用完即弃的工具加 MCP。
Q:加了 MCP server 后 Agent 的 token 用量为什么这么高?
几乎肯定是 schema 膨胀。冗长的工具定义每次请求都注入 context。审计你接的 server,只接需要的,优先选 schema 精简的。
Q:该用哪种传输,stdio 还是 HTTP?
同机器上的本地工具用 stdio(最简单,无网络)。跨网络边界的远程 server 用 Streamable HTTP。把传输匹配到 server 实际所在的位置。
Q:MCP server 是安全风险吗?
可能是。一个 MCP server 能代表你执行代码或访问数据。只接你信任的 server,严格限定权限,给任何运行不可信操作的东西加沙箱——跟你对待任何 Agent 能调用的工具一样谨慎。