生产级 AI Agent 为什么需要一个 Runtime 层
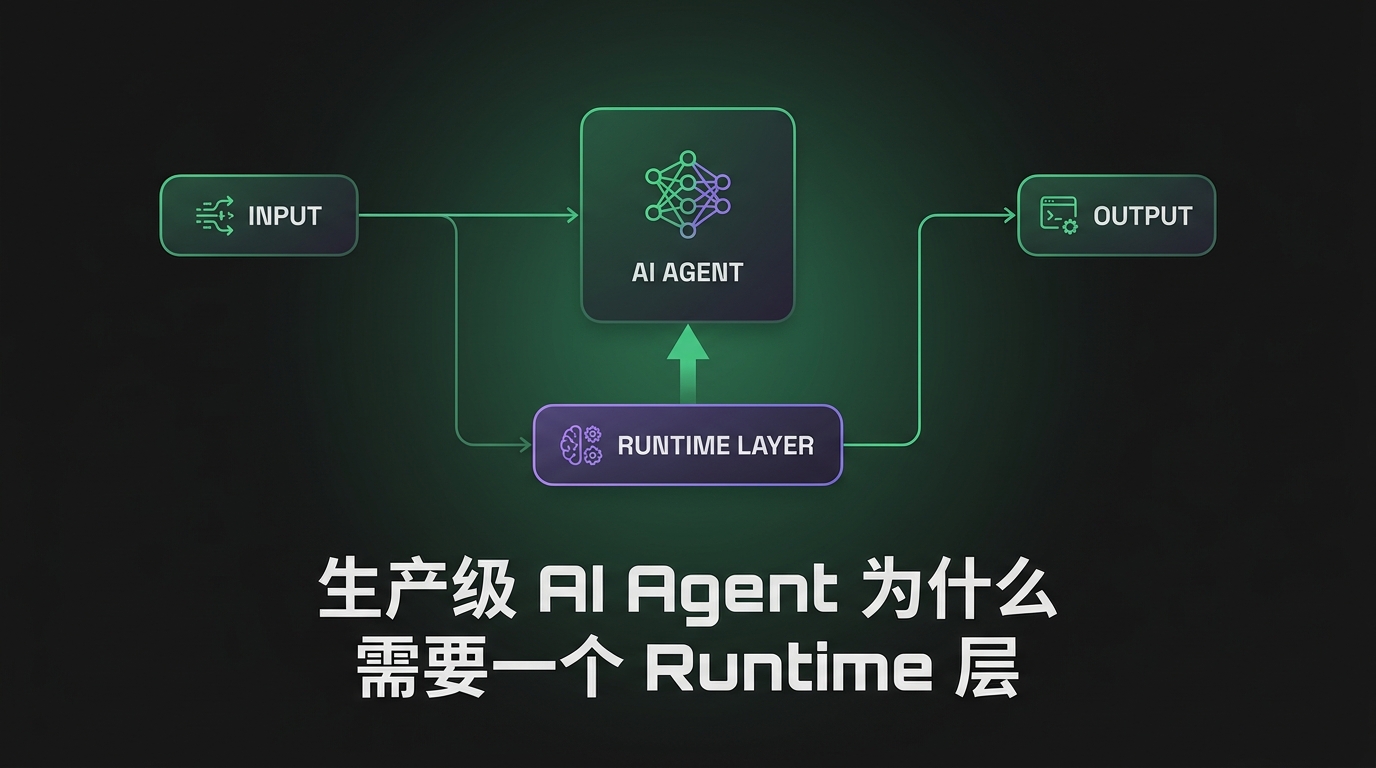
Agent runtime 层是夹在框架和模型之间的生产基础设施。它决定了持久性、隔离和恢复能力,本文讲清楚它是什么、怎么搭。
TL;DR — 框架决定你的 agent 下一步想什么,runtime 层决定这个想法能不能扛住一次崩溃、会不会
rm -rf掉你的主机、预算烧光了会不会停下来。大多数团队只搭了框架、跳过了 runtime,等上了生产才发现:模型 API 和框架既不管进程状态,也不管隔离和恢复。runtime 就是让一个长时间运行的 agent 保持持久、受控、可恢复的那一层。少了它,你的 agent 只是个一超时就死的 demo。
一个能跑的 demo 和一个生产级 agent,跑在完全不同的基础设施上,而两者之间的鸿沟就是 runtime 层。大多数「教你搭 agent」的教程止步于框架:接好一个推理循环、给几个工具、看它解决一个任务。这在你的笔记本上跑十分钟没问题,但它扛不住一个几小时的任务、一次进程重启、一次 prompt injection,或者一个停不下来的死循环。agent runtime 层就是处理这些的部分,也恰恰是没人给你讲的部分。
同样的翻车我见过两次:团队上线了一个 demo 里惊艳的 agent,结果生产第一周就趴窝。不是模型不行,也不是 prompt 写错了,而是底下根本没有 runtime。那个跑了 40 分钟的任务在第 38 分钟崩了,然后从零重来。那个生成清理脚本的 agent 把脚本跑在了错误的目录上。成本面板上显示有个任务循环了 4000 次才被人发现。这些都不是框架的 bug,是「缺 runtime」的 bug。
框架不等于 runtime
这两个概念经常被混为一谈,先把它们分开。像 LangChain 或 LangGraph 这样的框架是一个编排库:它组织推理循环、在内存里保存消息历史、决定下一步调用哪个工具。它运行在一个你启动的进程内部。
runtime 是这个进程周围的一切。它回答的是另一套问题:
- agent 的代码究竟在哪里执行,它能碰到什么?
- 如果主机在任务中途挂了,agent 是恢复还是从头再来?
- 是什么阻止一个循环永远跑下去、或者无限花 token?
- 怎么并发跑 500 个这样的 agent 还不让它们互相踩到对方?
框架假设了一个稳定、可信、单一的进程。而生产环境一个都不给你。runtime 就是来填这个缺口的,模型 API 肯定不会管,它是无状态的,两次调用之间什么都不记得。
runtime 层到底干什么
四项职责,框架和模型一个都不替你管:
| 职责 | 覆盖什么 | 缺了它会怎样 |
|---|---|---|
| 持久化状态 | checkpoint 进度,崩溃后恢复 | 一个 40 分钟的任务一出错就从零重来 |
| 隔离 | agent 代码运行的 sandbox | 一次 prompt injection 就摸到你的数据库凭证 |
| 资源控制 | CPU/内存上限、token 预算、步数上限 | 一个循环跑了 4000 次,账单全给你 |
| 生命周期 | 并发 agent 的创建、监管、回收 | 僵尸进程堆积,状态在任务间泄漏 |
注意这些全是运维层面的事,不是智能层面的事。模型再完美,这几个你照样一个都躲不掉。所以 runtime 和模型好不好是两码事,也所以拿更聪明的模型去治可靠性问题,从来都没用。
持久性:第一个把你绊倒的
agent 天生就是长时间运行的。coding agent 跑十分钟,research agent 跑一小时,自主 pipeline 跑一整天。任务越长,中途被打断的概率越高:一次部署、一次节点驱逐、一次 OOM kill、一次网络抖动。没有持久化状态,每被打断一次就得从头再来——对一个几小时的任务来说,从零重启不叫体验变差,叫直接报废。
解法是 durable execution(持久化执行):在每一步之后 checkpoint agent 的状态,让它能从停下的地方精确恢复。这在 2026 年已经不是什么稀罕东西了。有篇分析说得很直接:每个正经框架都已经默默承认 durable execution 是基本盘,LangGraph 出了 Postgres checkpointer,微软的 Durable Task 框架 也加了 agent 专用的 resume 原语。
但大多数团队搞错了一点:checkpoint 不等于 durable execution。把状态存进数据库是简单的那 80%。难的那 20% 是 runtime 保证工作流跑到完成、检测到崩溃、自动重新调度恢复,而不用你自己写恢复逻辑。Diagrid 团队把这个区别讲得很尖锐:他们认为 光有 checkpoint 是不够的,因为崩溃恢复应该由 runtime 而不是你的应用代码来负责。如果你的「持久性」不过是一个 try/except 重新加载状态,那你只搭了半个 runtime,剩下那半个,第一次出故障时自然就找上门了。
一个具体的 LangGraph checkpointer 长这样,这是有状态 agent 的最低门槛:
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.graph import StateGraph, START, END
from typing import TypedDict
class AgentState(TypedDict):
messages: list
step: int
def think(state: AgentState) -> AgentState:
# 一个推理步骤;实际场景里这里会调用你的模型
return {"messages": state["messages"], "step": state["step"] + 1}
# 基于 Postgres 的 checkpointer:每次节点转移都会被持久化
DB_URI = "postgresql://localhost:5432/agents?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 首次运行时创建 checkpoint 表
builder = StateGraph(AgentState)
builder.add_node("think", think)
builder.add_edge(START, "think")
builder.add_edge("think", END)
graph = builder.compile(checkpointer=checkpointer)
# thread_id 把一次运行和它的 checkpoint 历史绑定,复用它就能恢复
config = {"configurable": {"thread_id": "task-1742"}}
result = graph.invoke({"messages": [], "step": 0}, config)
print(result["step"])在 checkpoint 之后杀掉进程,再用同一个 thread_id 重新 invoke:它会从保存的状态恢复,而不是从头开始。这就是 runtime 在干活。注意这给你的是 checkpointing,不是像 Temporal 这种专用持久化引擎提供的「自动崩溃检测 + 重新调度」,这正好就是上面那条 80/20 的分界线。
隔离:搞砸了能让你丢饭碗的
agent 一旦能跑它自己写的代码,你就摊上了一个安全问题,而且不是假设,是实打实的。模型被一句恶意 prompt 一带偏,手里那个 shell 就成了攻击者的。这个话题值得单开一篇,我在 为什么自主 agent 需要安全 sandbox 里完整讲过,这里就一句话:runtime 就是隔离该待的地方。
框架能限制有哪些工具,可只要留着一个「运行 Python」的工具,整个攻击面就又全开了——偏偏 coding agent 离不开这个工具。隔离必须做在执行边界上,在框架底下。2026 年这个共识更硬了:共享内核的 Docker 已经压不住不可信的 agent 代码,大家转向 microVM(Firecracker、gVisor)做硬件级隔离。有篇文章记了一次真事故:一个 agent 突破了 Docker 容器 摸到了宿主机。runtime 要干的,就是让这种突破落进一个用完就扔的盒子,而不是你的基础设施。
资源控制与生命周期
不起眼的那两个。它们上不了头条,但它们正是「能跑 500 个并发 agent 的系统」和「跑到 20 个就趴窝的系统」之间的分界线。
资源控制就是给 agent 划一道它越不过去的硬上限:每个任务的 token 预算、墙钟超时、最大步数、sandbox 上的 CPU 和内存上限。agent 翻起车来特别费钱。一个推理循环一旦卡住不前,它会乐此不疲地一直重试,直到把账单刷成四位数。sandbox 是拿损害程度给爆炸半径封顶,runtime 则是拿钱给它封顶。
生命周期是脏活累活:给每个任务起一个隔离环境、盯着它跑、任务结束或挂了就干净地把它回收掉。这里 ephemerality(用完即弃)很关键——每个任务配一个全新环境,哪怕这一次跑歪了、被攻陷了,也污染不到下一次。这跟 cron 驱动的自主 agent 是同一个道理:每次定时跑都该是个干净的、用完就扔的盒子,而不是一台越攒越多状态和风险的长寿机器。
真出了问题的时候,你得能看见。资源控制和生命周期只有在可观测的前提下才有用,这也是为什么 agent 可观测性 是 runtime 的神经系统:它把「任务卡住了」变成一条 trace,清清楚楚显示是哪一步在循环、烧了多少 token。
自建还是买
你不会从零写一个 runtime,就像你不会从零写一个数据库。实际的问题是你要自己组装多少层。一个 2026 年的现实配置:
- 持久化执行:简单场景用框架 checkpointer(LangGraph + Postgres),需要保证完成和自动恢复时用专用引擎(Temporal、Restate)。
- 隔离:任何 agent 生成的代码都跑在基于 microVM 的 sandbox 里,自托管或用服务都行。
- 资源上限:在 sandbox 和编排层强制执行 token 预算、超时、步数上限。
- 生命周期和可观测性串起来:每次运行都干净地创建、干净地回收、全程被 trace。
这几层相对于模型和网关分别在哪一层,可以看完整的 AI Agent 基础设施技术栈。runtime 是大多数团队最后才发现、却最希望当初一开始就设计好的那一层。
行动建议:上线之前,先把三件事写下来——主机重启时,一个跑到一半的任务会怎样;agent 跑代码时能碰到哪些东西;又是什么拦着它别无限烧钱。这三个要是答不全,那你手里攥着的是个框架,不是 runtime,这个差别迟早会在生产环境里给你补上一课。
FAQ
什么是 agent runtime 层? 它是夹在 agent 框架和模型之间的生产基础设施,负责持久化状态、隔离、资源限制和进程生命周期。框架决定 agent 做什么,runtime 决定它能不能扛住崩溃、会不会伤到主机、预算用完会不会停。
我的框架不就已经是 runtime 了吗? 不是。像 LangGraph 这样的框架在一个可信的单进程内编排推理循环。它不沙箱化 agent 生成的代码、不保证崩溃恢复、也不强制主机级的资源上限。这些都是 runtime 的事,框架默认有别人来管。
简单的 agent 也需要 runtime 吗? 如果 agent 运行时间很短、不执行任何代码、丢了进度也无所谓,那大部分可以省掉。但只要任务跑到几分钟、执行生成的代码、或者按计划自主运行,每一块缺失的 runtime 都会变成一个等着发生的生产事故。
checkpoint 和 durable execution 有什么区别? checkpoint 是把状态存到存储里。durable execution 在这之上又加了一层 runtime 保证:工作流一定跑到完成,崩了能自动发现并重新调度恢复。存 checkpoint 是简单的那部分,真正把「靠谱的持久化 runtime」和「一个 try/except」拉开差距的,是那份恢复保证。
runtime 能买而不是自建吗? 基本上可以。状态用框架 checkpointer 或 Temporal 这样的持久化引擎,隔离用 microVM sandbox 服务,预算用你的编排层。你是在组装这些层,而不是从零写它们,就像你组装数据库和队列,而不是自己造一样。