Hermes 自我进化 Agent 的循环到底怎么工作的(2026)
拆解 Hermes Agent 2026 年的自我进化循环:技能生成机制、它到底持久化了什么、以及那个 40% 任务提速从哪来。
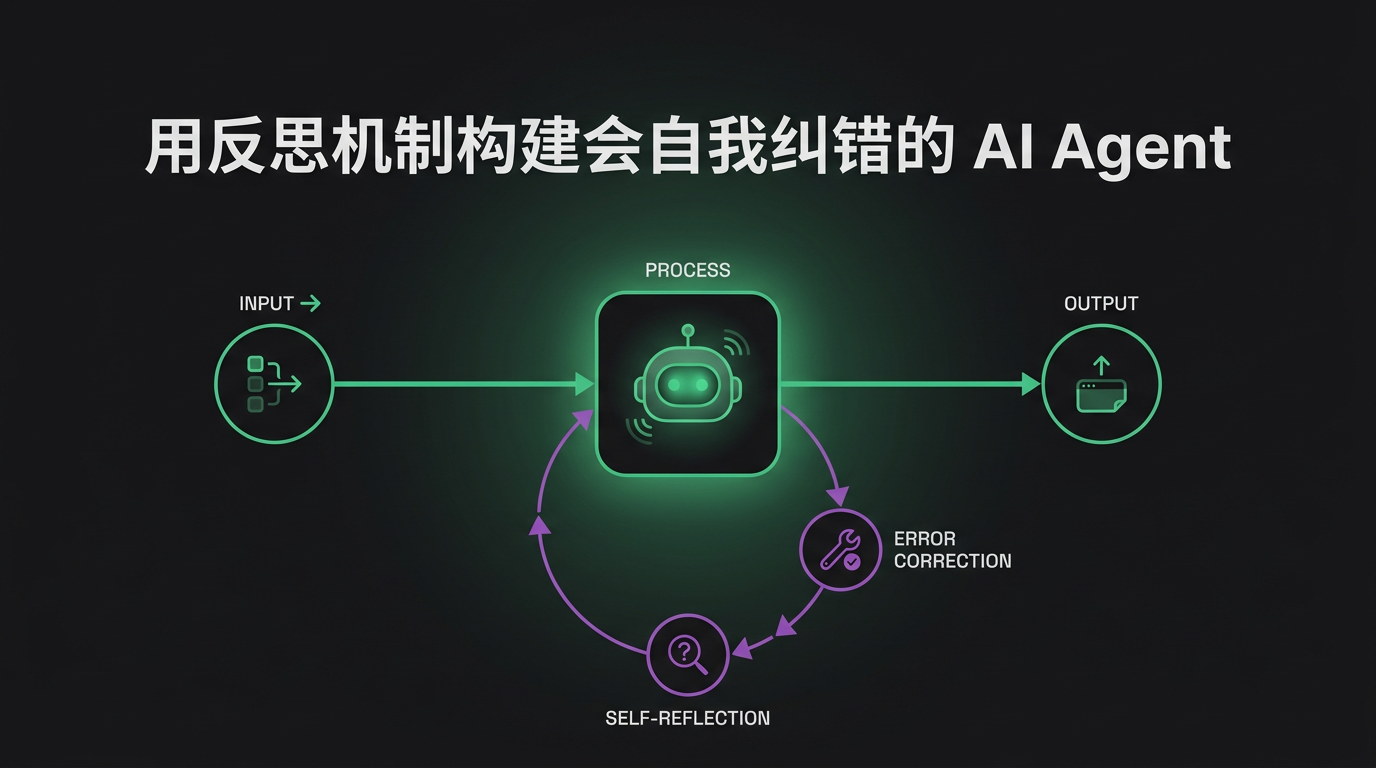
TL;DR — Hermes 的自我进化循环不是魔法。是三个具体机制协同工作:技能提取(把解决过的问题变成可复用文档)、分层记忆(跨 session 携带上下文)、nudge 系统(Agent 提醒自己把学到的东西存下来)。那个 40% 的任务提速来自不重复解决已经解决过的问题。下面讲真正的机制。
“自我进化”到底是什么意思
自我进化 Agent 指的是:在你不改代码、不改 prompt 的前提下,它在重复任务上变得肉眼可见地更好。这是 Nous Research 对 Hermes Agent 的宣称。和大多数”会学习的 AI”营销不同,这背后有真实的机制。
大多数 Agent 是失忆症患者。每个 session 从零开始。你要把项目结构、偏好、过去的决策——再讲一遍。Hermes 打破这个循环,把记忆和学习当作核心架构,而不是附加件。我深挖了它到底怎么工作的,因为”Agent 会学习”这种话通常一推敲就崩。这个基本站得住。
三个机制
1. 技能提取
这是头号特性。当 Hermes 解决一个非平凡问题——比如搞清楚把应用部署到一台难搞的 staging 服务器的精确命令序列——它可以把这个流程写成一份技能文档。技能就是结构化的 Markdown:什么时候用、步骤、以及过程中发现的坑。
下次类似任务出现时,相关技能加载进 context。Agent 不再从头推导,而是照着已经搞定的流程走。
# 技能:部署到 staging
## 何时使用
用户要求把当前项目部署到 staging。
## 步骤
1. 跑 `npm run build` —— 不设 NODE_ENV 会失败,所以前面加 NODE_ENV=production
2. staging 服务器第一次连接会拒绝;等 3 秒后重试一次
3. 健康检查端点是 /healthz,不是 /health(踩坑踩出来的)
## 坑
- staging 的 DB 迁移必须在部署前跑,不是部署后关键细节:那句”踩坑踩出来的”。技能捕获的不只是 happy path,还有 Agent 撞过又纠正的失败。复利价值就藏在这里。
2. 分层记忆
技能处理流程,记忆处理事实。Hermes 用两个 Markdown 文件:
user.md—— 关于你的持久事实。偏好、技术栈、时区、你喜欢的做事方式。memory.md—— 随时间累积的决策和上下文的长期记忆。
两个都在每次 session 开始时加载。这就是我在Agent 记忆架构深度对比里讲的”温记忆始终加载”模式——加载便宜、信号高、无检索延迟。
3. Nudge 系统
这是大多数人忽略的部分。一个能存技能的 Agent 不一定记得去存。Hermes 内置了自我提醒机制:完成复杂工作后,它会提示自己考虑这次经验值不值得持久化成技能或记忆更新。
没有这个,学习循环就停留在理论——能力存在但从不触发。Nudge 才是闭环的关键。这是个小东西,但作用很大,也是为什么 Hermes 的学习比那些技术上支持记忆但从不主动写入的框架更可靠。
那个 40% 从哪来
社区基准(TokenMix.ai)报告自动创建的技能能把研究类任务时间砍掉约 40%,对比全新 Agent 实例。这个数字听起来像营销,但机制很平凡:Agent 没有变聪明,只是没在重做已经做过的工作。
想想你自己的工作流。第一次给新项目配 CI 流水线,要试错好几个小时。第五次只要 20 分钟,因为你记得那些坑。Hermes 的技能库就是这种制度记忆,只不过是 Agent 的,而且在你扔给它的每个任务上复利累积。
代价:第一天优势为零。全新装的 Hermes 不比任何其他 Agent 强。那 40% 是个随技能库增长而逼近的渐近线。第一周看不出啥,第三个月差距就明显了。
和 Anthropic 的 Dreaming 比
Anthropic 在 2026 年 5 月给 Claude Managed Agents 上线了 “Dreaming”——一个 Agent 回顾过去 session、策展自己记忆的后台进程。听起来跟 Hermes 像,但机制不同:
| 维度 | Hermes Skills | Anthropic Dreaming |
|---|---|---|
| 触发 | 主动,任务中/后 | 定时后台进程 |
| 产出 | 可复用流程文档 | 策展/改写的记忆存储 |
| 托管 | 自托管,你拥有 | Anthropic 托管 |
| 可见性 | 你能读/改技能文件 | 不透明的整合 |
| 成本模型 | 你的推理成本 | 额外的后台 LLM 调用 |
Dreaming 让 Agent 记得更好。Hermes skills 让它在重复任务上执行更快。两者互补——原则上你可以用启用了 Dreaming 的 Claude 模型来跑 Hermes,两个都拿到。
用任意模型跑
Hermes 是模型无关的——用任何 OpenAI 兼容端点作为推理引擎。这对自我进化循环很重要,因为技能质量高度依赖做提取的模型。弱模型写出含糊没用的技能,强模型写出精确可复用的。
把 Hermes 指向 SandBase,可以按角色混用模型:
# cli-config.yaml
providers:
- name: sandbase
api_base: https://api.sandbase.ai/v1
api_key: ${SANDBASE_API_KEY}
models:
- anthropic/claude-sonnet-4 # 主推理 + 写技能
- google/gemini-2.5-flash # 便宜快速的日常任务一个实用模式:用强模型(Claude Sonnet)跑主循环和技能提取,用便宜模型(Gemini Flash)做日常总结。强模型写出的技能即使由便宜模型执行也持续受益。
值得吗
如果你跟 Agent 的工作是一次性、零散的,自我进化循环只增加开销没多少回报——你永远碰不到同一个任务两次。如果你的工作是重复的(同一个代码库、同样的部署目标、同类研究),复利是真实且可观的。
实话:Hermes 的学习循环是我见过最可信的”会变好的 Agent”实现,恰恰因为它底层很无聊。没有涌现智能,没有挥手糊弄。就是技能文件、记忆文件、加一个提醒去写它们的 nudge。能落地的无聊机制,胜过落不了地的炫酷机制。
FAQ
Q:Hermes 真的会学习,还是只是缓存?
更接近缓存流程,而非 ML 意义上的学习。没有权重更新或微调。它写可复用的技能文档,相关时加载。叫不叫”学习”是文字游戏——实际效果是它不再重复解决已解决的问题。
Q:技能会过时或出错吗?
会。如果你的部署流程变了,旧技能会主动误导 Agent。因为技能是你能读能改的纯 Markdown,你可以剪枝或修正。把技能库当代码对待——需要偶尔维护。
Q:这跟写好的 system prompt 有什么区别?
system prompt 是静态的,你手动维护。技能是 Agent 从真实经验(包括撞过的失败)里写出来的。Agent 自己长出 playbook,而不是你提前预测它会需要的一切。
Q:自我进化循环需要强模型吗?
技能提取需要——弱模型写含糊技能没帮助。技能执行用便宜模型通常够。跨模型分角色(通过 SandBase 这种路由)是性价比的甜点区。
Q:技能和记忆存在哪?
作为纯 Markdown 文件存在你跑 Hermes 的基础设施上。你完全拥有——无厂商锁定,无不透明云存储。这是自托管的好处;坏处是备份得你自己负责。