DeerFlow 详解:字节跳动的长周期 SuperAgent Harness
DeerFlow 是什么、字节跳动如何构建开源 SuperAgent Harness 处理多小时任务,以及 'harness' 对 2026 年 Agent 基础设施的意义。
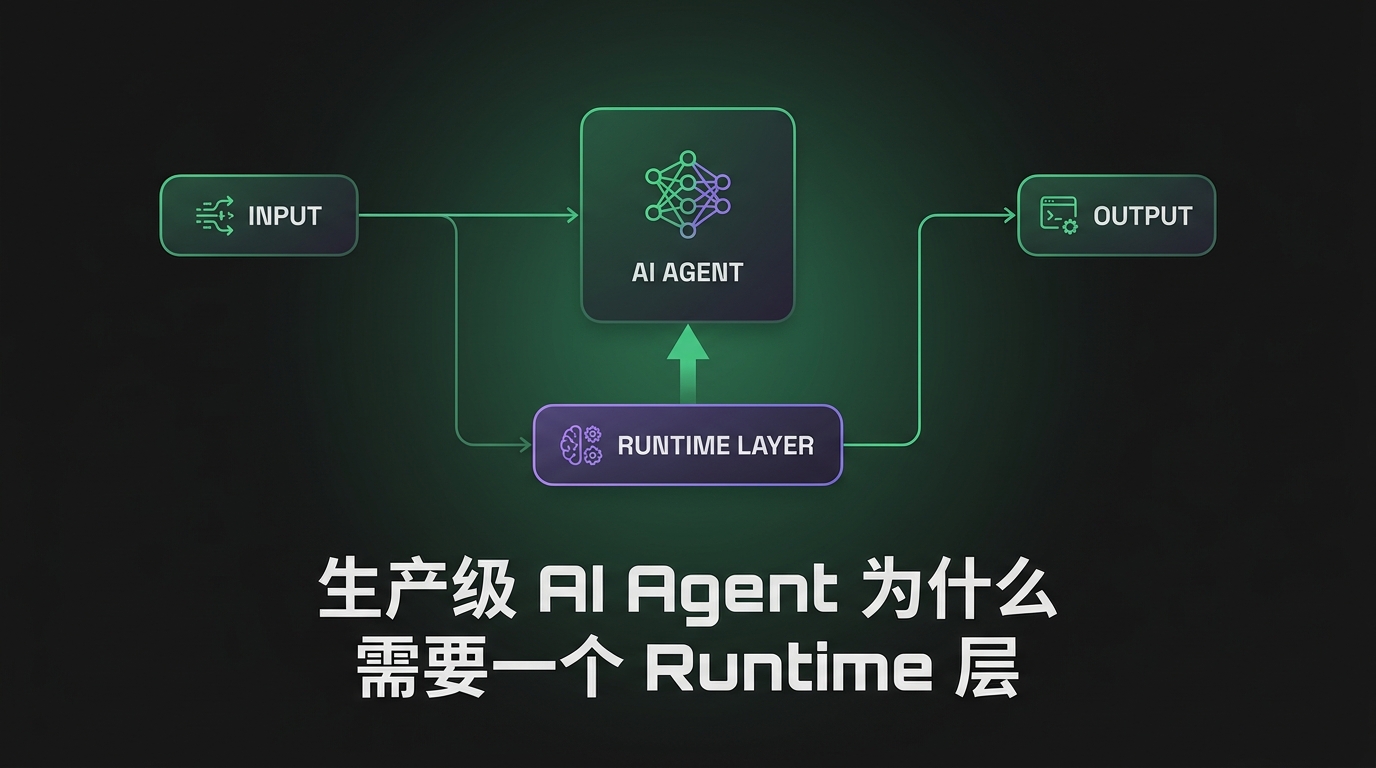
TL;DR — DeerFlow(Deep Exploration and Efficient Research Flow)是字节跳动的开源 “SuperAgent harness”——一个给 AI Agent 提供自己电脑的运行时:Docker 沙箱、持久文件系统、长期记忆、子 Agent 生成和技能系统。它处理耗时几分钟到几小时的任务,不是几秒的。2026 年 2 月登顶 GitHub Trending,突破 37K stars。“Harness” 这个概念是关键——它不是构建 Agent 的框架,是运行 Agent 的基础设施。
“Harness” 是什么意思
DeerFlow 的自我描述用了一个在 2026 年 Agent 生态越来越常见的词:harness。
Framework 给你搭建模块。Harness 给你预装好的运行时。区别很重要:
| Framework | Harness | |
|---|---|---|
| 你提供 | Agent 逻辑、工具、记忆、基础设施 | Agent 逻辑(“做什么”) |
| 它提供 | 待组装的组件 | 可直接使用的运行时(沙箱、记忆、工具、子 Agent) |
| 类比 | 宜家家具套件 | 精装公寓 |
| 例子 | LangChain, Mastra, CrewAI | DeerFlow, LobeHub |
DeerFlow 的论点:如果你想让 Agent 在一个复杂任务上工作几小时(研究一个主题、写代码、建网站),你不能指望它自带基础设施。Harness 提供:
- Docker 沙箱安全执行代码
- 跨步骤存活的持久文件系统
- 覆盖整个任务的长期记忆
- 生成子 Agent 并行工作的能力
- 可扩展能力的技能系统
- 多渠道交互的消息网关
架构
┌──────────────────────────────────────────────────┐
│ 用户 / 触发器 │
│ (聊天, API, cron, webhook) │
├──────────────────────────────────────────────────┤
│ 编排器 │
│ 规划任务,拆解为子任务 │
├──────────────────────────────────────────────────┤
│ 子 Agent │
│ ├── 研究者(网络搜索、爬取) │
│ ├── 编码者(代码生成、执行) │
│ ├── 创作者(内容、报告、网页) │
│ └── 自定义(用户定义的技能) │
├──────────────────────────────────────────────────┤
│ 运行时基础设施 │
│ ├── Docker 沙箱(隔离代码执行) │
│ ├── 持久文件系统(文件跨步骤存活) │
│ ├── 记忆(长期上下文,向量存储) │
│ ├── 工具(网络、文件、代码、API) │
│ └── 消息网关(Slack、Web、API) │
└──────────────────────────────────────────────────┘编排器是”大脑”——接收高级任务,分解为子任务,分配给专业子 Agent,协调结果。子 Agent 共享同一个沙箱和文件系统,一个 Agent 写的文件另一个可以读。
什么是”长周期”
大多数 Agent 在单轮对话尺度工作:你问它答。DeerFlow 针对的是根本不同时间尺度的任务:
| 时间尺度 | 示例任务 | 需要什么 |
|---|---|---|
| 秒 | ”翻译这句话” | 只要模型 |
| 分钟 | ”修这个 bug” | 模型 + 工具调用 |
| 小时 | ”研究竞争对手格局并写报告” | 编排、记忆、持久化、并行子 Agent |
| 天 | ”构建并部署这个微服务” | 以上全部 + 调度、checkpoint、人工审查门 |
在小时到天的尺度,你会撞到短交互中不存在的问题:
- 上下文溢出 — 对话历史超出任何模型的上下文窗口
- 状态丢失 — Agent 或基础设施重启,工作丢了
- 一致性漂移 — 跨很多步骤后 Agent 失去对总体目标的追踪
- 资源泄漏 — 长时间运行的沙箱累积文件、进程、连接
DeerFlow 用持久记忆(重启后存活)、checkpoint(从断点恢复)和结构化任务分解(让每个子 Agent 聚焦有限子问题)来应对。
技能系统
技能是 DeerFlow 的扩展机制。一个技能是打包好的 Agent 能力:
- 网络搜索 — 在网上搜索和爬取信息
- 代码执行 — 在沙箱中编写和运行代码
- 文件操作 — 读写和组织文件
- 内容创作 — 生成报告、文章、演示文稿
- 自定义 — 你定义和注册的任何能力
技能和工具不同。工具是单个函数(如 search_web(query))。技能是更高级的能力,可能涉及多次工具调用、子 Agent 编排和有状态逻辑(如”研究一个主题”涉及多次搜索、爬取、总结、交叉引用)。
实际用例
DeerFlow 的文档和社区展示这类任务:
-
深度研究 — “研究 2026 年 Agent 技术趋势,产出带引用的 20 页报告。” Agent 搜索、爬取源头、交叉引用、写大纲、撰写、格式化。
-
代码项目生成 — “建一个 Next.js 仪表盘显示实时加密货币价格。” Agent 创建文件、安装依赖、写组件、测试、迭代。
-
内容创作 — “创建一个预测 Agent 技术机会的网页。” Agent 调研、设计、编码、部署。
这些是人类开发者需要 2-8 小时的任务。DeerFlow 不是瞬间完成——通常需要 30-120 分钟——但它自主执行,几乎不需要人工干预。
长周期 Agent 一个不太舒服的真相
这里我得对整个品类说点实在话,不只是 DeerFlow。“给个任务,回来收一份成品报告”的演示确实唬人。但那也是跑得最好的那一次,而最好情况和中位情况之间的差距,比营销承认的要大。
我反复见到的、小时级自主任务的失败模式不是崩溃,是看似合理的漂移。Agent 不报错——它自信地产出一个 80% 对、20% 微妙错的东西,而因为没人盯着中间步骤,那 20% 埋在很难找的地方。一份四十条真引用里混了三条捏造引用的研究报告,比没有报告更糟,因为它看起来可信。
周期越长,这越是复利累积。每一步的小错成了下一步的输入假设。到第 40 步,Agent 可能在自信地基于它第 12 步得出的错误结论往上搭。DeerFlow 的 checkpoint 和记忆帮的是连续性(不丢工作),帮不了正确性(不传播错误)。这是两个不同的问题,而第二个还没解决。
所以像 DeerFlow 这种工具的现实用法不是”发出去然后信结果”,而是”发出去,然后像审一个初级员工的初稿那样苛刻地审输出”。它省你打字和苦力调研,省不了判断。对那些能廉价验证结果的任务(代码要么过测试要么不过),价值很高。对那些验证和干活一样贵的任务(一份你得逐源重核的研究综合),价值就比演示暗示的要模糊。
在生态中的位置
DeerFlow 和 Agent 框架、coding agent 都不在同一个位置:
| 项目 | 是什么 | 时间尺度 |
|---|---|---|
| LangGraph | Agent 编排框架 | 你用它来搭 |
| Claude Code | Coding agent (CLI) | 每个任务几分钟 |
| OpenHands | Coding agent (全栈) | 每个任务几分钟 |
| Dify | 可视化 agent 工作流 | 每个工作流几分钟 |
| DeerFlow | 长周期运行时 harness | 每个任务几分钟到几小时 |
| Devin | 商业长周期 agent | 每个任务几小时 |
DeerFlow 在野心上最接近 Devin(长时间自主任务),但开源且可自托管。在架构上最接近 OpenHands(基于沙箱的执行),但范围更广(不只是编码——还有研究、内容、任何基于技能的任务)。
沙箱连接
DeerFlow 的沙箱是核心。每个代码执行都在 Docker 容器里发生。Agent 拥有完整 Linux 环境:shell、文件系统、网络、Python、Node.js——任务需要什么就有什么。
这和 OpenHands 以及更广泛的沙箱化 Agent 执行运动是同一个架构原则。Agent 生成代码,沙箱安全运行,输出反馈给 Agent 推理。
对 SandBase 这样的 Agent 基础设施平台,DeerFlow 代表一个潜在的集成点:提供 sandbox-as-a-service 给 DeerFlow 的编排器调用做代码执行,而不是要求用户自己管理 Docker 基础设施。
AI Agent 基础设施技术栈的一部分
DeerFlow 是 2026 AI Agent 基础设施技术栈 的框架层 harness。同集群相关阅读:
- LangChain 与 LangGraph — 你会用来搭类似 harness 的编排框架。
- Mastra — TypeScript 优先的框架替代品。
FAQ
DeerFlow 生产就绪了吗?
字节跳动内部在用。开源版功能完整但仍在快速迭代(2.0 是最近的)。适合实验和内部工具;面向客户的生产环境需要仔细评估稳定性。
支持什么模型?
通过 OpenAI 兼容接口模型无关。支持 GPT-4o、Claude、Gemini、DeepSeek、Qwen 以及任何兼容 API 可访问的模型。
和直接用 Claude Code 做长任务比呢?
Claude Code 是 coding agent——写代码和跑代码。DeerFlow 是编排多种能力的 harness:研究、编码、内容创作、文件管理。Claude Code 可以是 DeerFlow 的子 Agent 之一。它们在不同抽象层。
能加自己的技能吗?
可以。技能系统可扩展。定义技能的能力,注册它,编排器就可以分配任务给它。
需要 GPU 吗?
不需要。DeerFlow 是编排层——远程调 LLM API。需要 CPU/RAM 给沙箱(Docker)和编排器,但本地不需要 GPU。
核心要点
- DeerFlow 是字节跳动的开源 “SuperAgent harness”——面向耗时分钟到小时的任务的运行时。开箱提供沙箱、记忆、子 Agent 和技能。
- “Harness” 概念和 “framework” 不同:你带 Agent 逻辑,它带基础设施。更少组装,更即时的执行能力。
- 长周期任务需要短交互循环提供不了的架构能力(持久化、checkpoint、子 Agent 协调、记忆管理)。
- 37K+ stars 和 GitHub Trending #1,代表着对在长时间做真实工作(不只是回答问题)的 Agent 的增长需求。
- 沙箱架构直接连接更广泛的 Agent infra 趋势:执行代码的 Agent 需要隔离,而这种隔离正在成为标准基础设施服务。