Connecting MCP Servers to Your AI Agent (2026 Guide)
A practical guide to connecting MCP servers to your AI agent in 2026: transports, the connection lifecycle, real config, and the schema-bloat gotcha that costs you tokens.
TL;DR — MCP (Model Context Protocol) is how agents talk to tools in a standardized way. Connecting an MCP server is three steps: pick a transport (stdio for local, Streamable HTTP for remote), declare the server in your agent’s config, and let the agent discover the tools. The gotcha nobody warns you about: verbose tool schemas can cost 30x more tokens than the equivalent CLI. Here’s how to do it right.
What Problem MCP Actually Solves
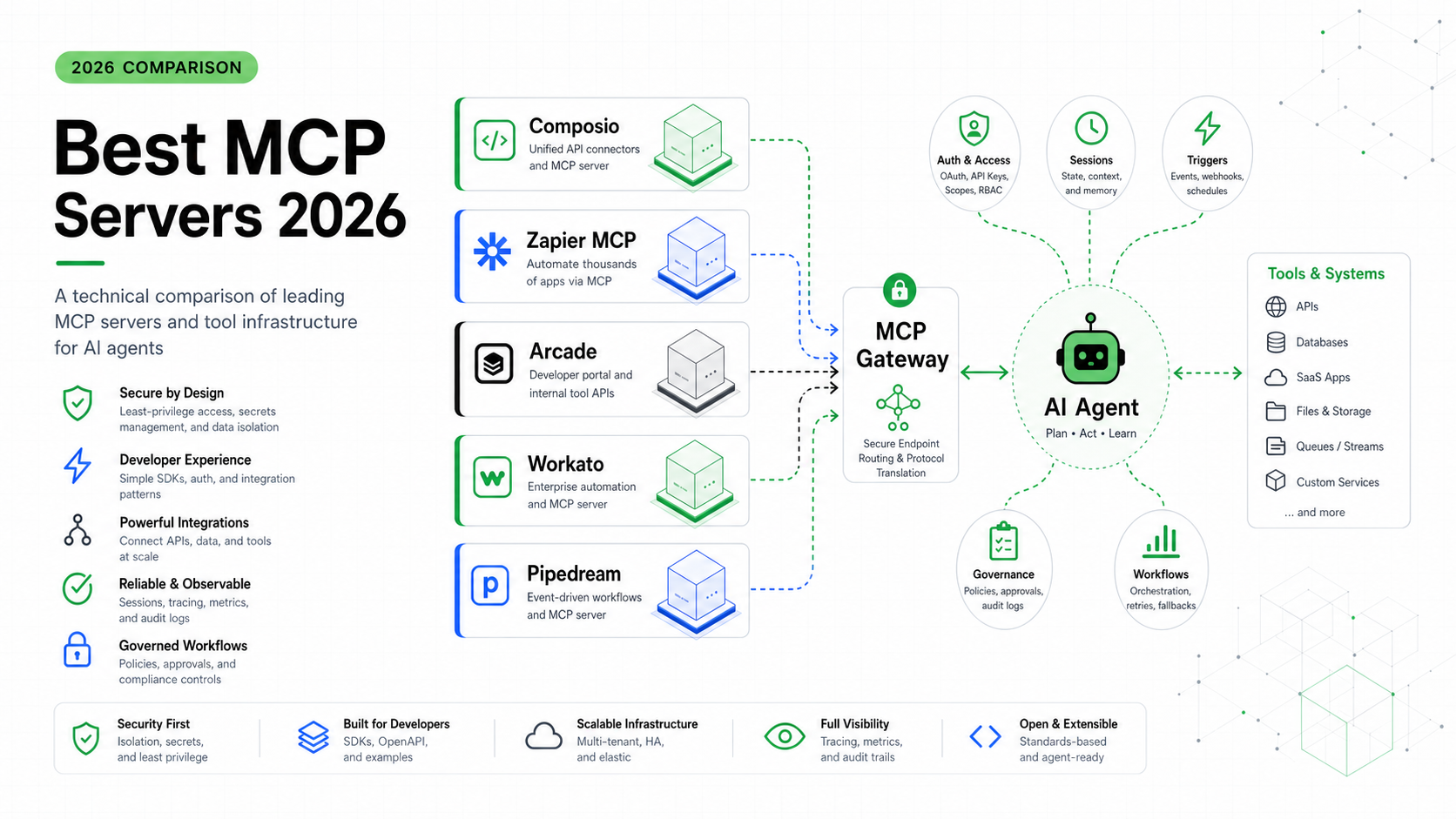
Before MCP, every agent framework had its own way of defining tools. Write a tool for LangChain, rewrite it for AutoGen, rewrite it again for your custom agent. Connecting MCP servers to your agent solves this: define a tool once as an MCP server, and any MCP-compatible agent can use it. It’s USB-C for agent tools — one standard, many devices. (The official MCP specification is the canonical reference.)
In 2026, MCP has gone from “interesting Anthropic proposal” to the de facto standard. Claude Code has the deepest MCP integration, but OpenClaw, Hermes, and most serious frameworks speak it now. If you’re building agents, you’ll connect MCP servers. Here’s the practical mechanics.
The Two Transports You Need to Know
MCP defines how an agent (client) and a tool server communicate. There are two transports that matter:
stdio — For Local Servers
The server runs as a subprocess on the same machine, communicating over standard input/output. This is the simplest and most common setup for local tools — file system access, local databases, shell commands. (The reference MCP servers are a good starting point.)
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/path/to/dir"]
}
}
}The agent spawns the subprocess, pipes JSON-RPC messages over stdio, and shuts it down when done. No network, no ports, minimal attack surface.
Streamable HTTP — For Remote Servers
When the MCP server lives elsewhere — a shared team service, a SaaS integration, a containerized tool — you use Streamable HTTP. This replaced the older HTTP+SSE transport and is the standard for remote MCP in 2026.
{
"mcpServers": {
"company-api": {
"url": "https://mcp.yourcompany.com/mcp",
"headers": {
"Authorization": "Bearer ${MCP_TOKEN}"
}
}
}
}Rule of thumb: stdio for anything on your machine, Streamable HTTP for anything across a network boundary. Don’t expose a stdio server over the network with a janky wrapper — use the transport designed for it.
Quick reference for choosing a transport:
| stdio | Streamable HTTP | |
|---|---|---|
| Server location | Same machine | Remote / networked |
| Setup complexity | Minimal | Needs URL + auth |
| Attack surface | None (no ports) | Network-exposed |
| Best for | Local files, shell, DBs | Shared team services, SaaS |
| Auth | OS-level | Bearer token / headers |
The Connection Lifecycle
When your agent connects to an MCP server, four things happen in order:
- Initialize — Client and server handshake, exchanging protocol versions and capabilities.
- Discovery — The agent asks “what tools do you have?” The server returns tool definitions with names, descriptions, and JSON Schema for inputs.
- Invocation — When the model decides to use a tool, the agent sends a
tools/callrequest with arguments. The server executes and returns the result. - Teardown — On session end, the connection closes cleanly (subprocess killed for stdio, HTTP connection closed for remote).
Understanding discovery is key: the tool schemas the server returns get injected into the model’s context. That’s convenient — but it’s also where the cost hides.
The Schema Bloat Gotcha
Here’s the thing nobody puts in the quickstart: MCP tool schemas can be shockingly token-expensive. A verbose MCP server might describe a tool with deeply nested JSON Schema, enums, descriptions for every field, and examples — and all of that gets loaded into context on every single request, whether the tool is used or not.
In practice, a poorly designed MCP server can cost 30x more tokens than the equivalent CLI command for the same capability. If you connect ten chatty MCP servers, you can burn thousands of tokens on tool definitions before the model does any actual work.
Mitigations that actually help:
- Connect only the servers you need for a given task. Don’t load your entire MCP catalog into every session.
- Prefer servers with lean schemas. A tool with a 5-line schema beats one with a 50-line schema doing the same job.
- Use tool filtering if your framework supports it — expose only the specific tools an agent needs, not the server’s entire surface.
- Watch your token usage. If your agent’s input tokens are mysteriously high, audit your MCP tool definitions first.
A Real Connection, End to End
Here’s connecting a filesystem server and a remote API server to an agent, then verifying the tools are discovered:
# Pseudocode for the connection flow most frameworks follow
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
server_params = StdioServerParameters(
command="npx",
args=["-y", "@modelcontextprotocol/server-filesystem", "/data"]
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
# Discovery: list available tools
tools = await session.list_tools()
for tool in tools.tools:
print(f"{tool.name}: {tool.description}")
# Invocation: call a tool
result = await session.call_tool(
"read_file",
arguments={"path": "/data/notes.txt"}
)
print(result.content)The model never sees this plumbing — it just sees the discovered tools as available functions and calls them by name. Your job is to wire the connection and manage which servers are active.
Where the Model Comes In
The MCP server provides tools; the model decides when to use them. That decision quality depends heavily on the model — a strong model reads a tool schema and uses it correctly; a weak one mis-calls tools or ignores them.
This is where routing helps. Pointing your agent at SandBase lets you use a capable model for tool-heavy reasoning while keeping costs down on simpler turns:
OPENAI_API_BASE=https://api.sandbase.ai/v1
OPENAI_API_KEY=your-sandbase-api-key
MODEL=anthropic/claude-sonnet-4 # strong tool-calling for MCP-heavy workFunction calling is a capability that varies a lot between models, so having 300+ behind one endpoint lets you match the model to the tool-use demands of the task. (If you’re choosing a coding agent with deep MCP support, Claude Code leads on MCP integration.)
FAQ
Q: MCP vs function calling — what’s the difference?
Function calling is the model capability (the model emitting a structured request to call a tool). MCP is the protocol for how tools are defined, discovered, and served. MCP uses function calling under the hood but standardizes the tool plumbing so tools are reusable across agents.
Q: Do I need MCP, or can I just define tools directly?
If your tools are one-off and used by one agent, defining them directly is simpler. MCP pays off when you want tools reusable across multiple agents or shared across a team. Don’t add MCP for a single throwaway tool.
Q: Why is my agent’s token usage so high after adding MCP servers?
Almost certainly schema bloat. Verbose tool definitions get injected into context on every request. Audit your connected servers, connect only what you need, and prefer servers with lean schemas.
Q: Which transport should I use, stdio or HTTP?
stdio for local tools running on the same machine (simplest, no network). Streamable HTTP for remote servers across a network boundary. Match the transport to where the server actually lives.
Q: Are MCP servers a security risk?
They can be. An MCP server can execute code or access data on your behalf. Only connect servers you trust, scope their permissions tightly, and sandbox anything that runs untrusted operations — the same caution you’d apply to any tool an agent can invoke.