DeerFlow Explained: ByteDance's SuperAgent Harness
What DeerFlow is, how ByteDance built an open-source SuperAgent harness for multi-hour tasks, and what 'harness' means for agent infrastructure in 2026.
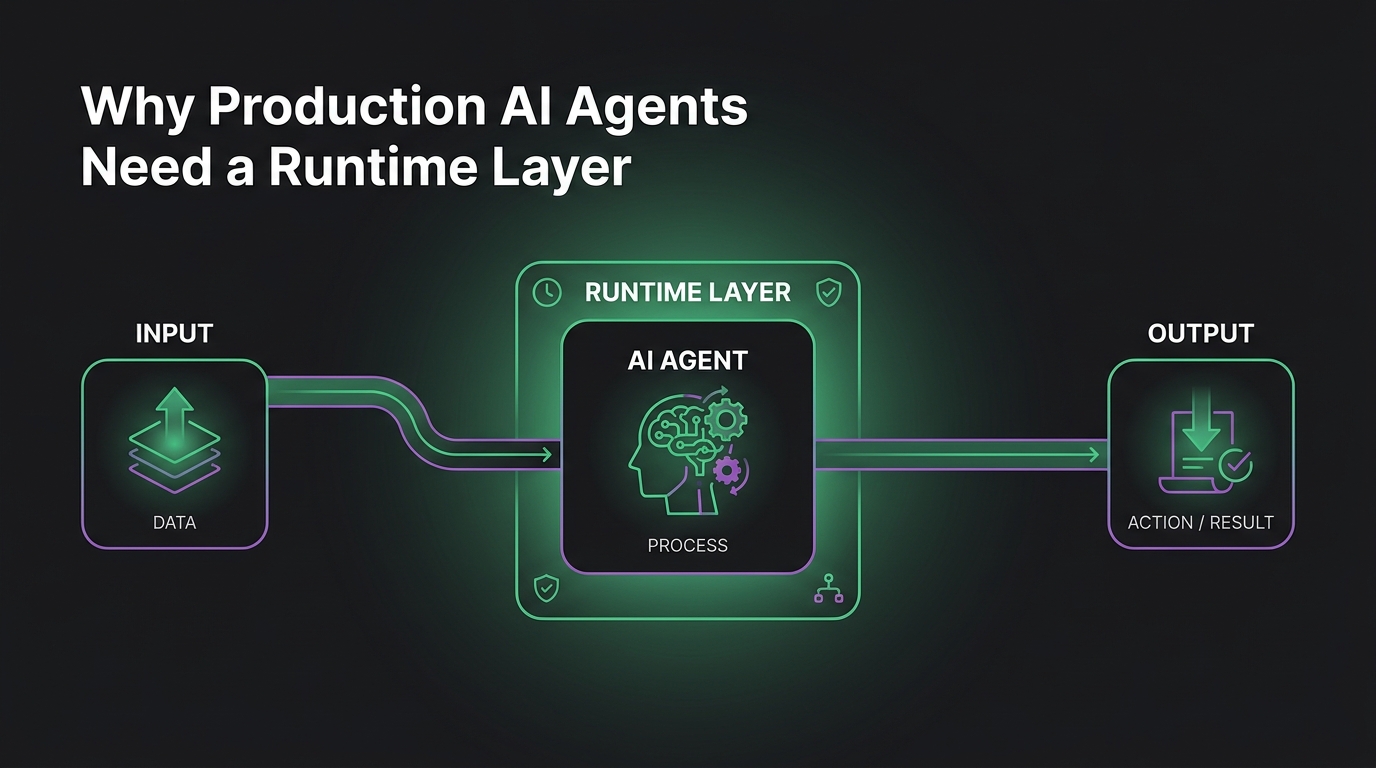
TL;DR — DeerFlow (Deep Exploration and Efficient Research Flow) is ByteDance’s open-source “SuperAgent harness” — a runtime that gives AI agents their own computer: Docker sandbox, persistent filesystem, long-term memory, sub-agent spawning, and skills. It handles tasks that take minutes to hours, not seconds. Hit #1 on GitHub Trending in February 2026 and crossed 37K stars. The concept of “harness” is the key — it’s not a framework for building agents, it’s infrastructure for running them at long horizons.
What “Harness” Means
DeerFlow’s self-description uses a word that’s becoming common in 2026’s agent ecosystem: harness.
A framework gives you building blocks. A harness gives you a pre-wired runtime. The distinction matters:
| Framework | Harness | |
|---|---|---|
| You provide | Agent logic, tools, memory, infra | Agent logic (the “what”) |
| It provides | Components to assemble | Ready-to-use runtime (sandbox, memory, tools, sub-agents) |
| Analogy | IKEA furniture kit | A furnished apartment |
| Examples | LangChain, Mastra, CrewAI | DeerFlow, LobeHub |
DeerFlow’s thesis: if you want an agent to work for hours on a complex task (research a topic, write code, build a website), you can’t expect it to bring its own infrastructure. The harness provides:
- A Docker sandbox where it can run code safely
- A persistent filesystem that survives across steps
- Long-term memory that spans the entire task
- The ability to spawn sub-agents for parallel work
- A skill system for extensible capabilities
- A message gateway for multi-channel interaction
Architecture
┌──────────────────────────────────────────────────┐
│ User / Trigger │
│ (chat, API, cron, webhook) │
├──────────────────────────────────────────────────┤
│ Orchestrator │
│ Plans the task, breaks into sub-tasks │
├──────────────────────────────────────────────────┤
│ Sub-Agents │
│ ├── Researcher (web search, crawling) │
│ ├── Coder (code generation, execution) │
│ ├── Creator (content, reports, websites) │
│ └── Custom (user-defined skills) │
├──────────────────────────────────────────────────┤
│ Runtime Infrastructure │
│ ├── Docker Sandbox (isolated code execution) │
│ ├── Persistent FS (files survive across steps) │
│ ├── Memory (long-term context, vector store) │
│ ├── Tools (web, file, code, API) │
│ └── Message Gateway (Slack, web, API) │
└──────────────────────────────────────────────────┘The orchestrator is the “brain” — it takes a high-level task, decomposes it into sub-tasks, assigns them to specialized sub-agents, and coordinates results. Sub-agents share the same sandbox and filesystem, so one agent can write a file that another reads.
What Makes It “Long-Horizon”
Most agents work at the scale of a single conversation turn: you ask, it responds. DeerFlow targets tasks at a fundamentally different timescale:
| Timescale | Example task | What’s needed |
|---|---|---|
| Seconds | ”Translate this sentence” | Just a model |
| Minutes | ”Fix this bug” | Model + tool calling |
| Hours | ”Research competitor landscape and write report” | Orchestration, memory, persistence, parallel sub-agents |
| Days | ”Build and deploy this microservice” | All of the above + scheduling, checkpointing, human review gates |
At the hours-to-days timescale, you hit problems that don’t exist in short interactions:
- Context overflow — The conversation history exceeds any model’s context window
- State loss — If the agent or infrastructure restarts, work is lost
- Coherence drift — The agent loses track of the overall goal across many steps
- Resource leaks — Long-running sandboxes accumulate files, processes, connections
DeerFlow addresses these with persistent memory (survives restarts), checkpointing (resume from where it left off), and a structured task decomposition that keeps each sub-agent focused on a bounded sub-problem. The DeerFlow documentation covers the architectural rationale in detail.
The Skill System
Skills are DeerFlow’s extension mechanism. A skill is a packaged capability the agent can use:
- Web search — Search and crawl the internet for information
- Code execution — Write and run code in the sandbox
- File manipulation — Read, write, and organize files
- Content creation — Generate reports, articles, presentations
- Custom — Any capability you define and register
Skills are different from tools. A tool is a single function (e.g., search_web(query)). A skill is a higher-level capability that might involve multiple tool calls, sub-agent orchestration, and stateful logic (e.g., “research a topic” involves multiple searches, crawling, summarizing, cross-referencing).
Real-World Use Cases
DeerFlow’s documentation and community showcase tasks like:
-
Deep research — “Research the agent technology trends for 2026 and produce a 20-page report with citations.” The agent searches, crawls sources, cross-references, outlines, writes, and formats.
-
Code project generation — “Build a Next.js dashboard that shows real-time crypto prices.” The agent creates files, installs dependencies, writes components, tests, and iterates.
-
Content creation — “Create a webpage forecasting agent technology opportunities.” The agent researches, designs, codes, and deploys.
These are tasks that would take a human developer 2-8 hours. DeerFlow doesn’t do them instantly — it also takes time (often 30-120 minutes) — but it does them autonomously with minimal human intervention.
The Uncomfortable Truth About Long-Horizon Agents
Here’s where I have to be honest about the category, not just DeerFlow. The demos of “give it a task, come back to a finished report” are genuinely impressive. They’re also the best-case runs, and the gap between best-case and median-case is wider than the marketing admits.
What I’ve consistently seen with hours-long autonomous tasks: the failure mode isn’t a crash, it’s plausible drift. The agent doesn’t error out — it confidently produces something that’s 80% right and 20% subtly wrong, and because no human was watching the middle steps, the 20% is buried where it’s expensive to find. A research report with three fabricated citations among forty real ones is worse than no report, because it looks trustworthy.
The longer the horizon, the more this compounds. Each step’s small error becomes the next step’s input assumption. By step 40, an agent can be confidently building on a wrong conclusion it reached at step 12. DeerFlow’s checkpointing and memory help with continuity (not losing work) but they don’t help with correctness (not propagating a mistake). Those are different problems, and the second one is unsolved.
This is why the realistic use of a tool like DeerFlow isn’t “fire it and trust the output.” It’s “fire it, then review the output as critically as you’d review a junior’s first draft.” It saves you the typing and the grunt research, not the judgment. For tasks where you can cheaply verify the result (code that either passes tests or doesn’t), the value is high. For tasks where verification is as expensive as the work (a research synthesis you’d have to re-check source by source), the value is murkier than the demo suggests.
Where DeerFlow Fits in the Ecosystem
DeerFlow occupies a distinct position from both agent frameworks and coding agents:
| Project | What it is | Timescale |
|---|---|---|
| LangGraph | Agent orchestration framework | You build with it |
| Claude Code | Coding agent (CLI) | Minutes per task |
| OpenHands | Coding agent (full-stack) | Minutes per task |
| Dify | Visual agent workflow builder | Minutes per workflow |
| DeerFlow | Long-horizon runtime harness | Minutes to hours per task |
| Devin | Commercial long-horizon agent | Hours per task |
DeerFlow is closest to Devin in ambition (long-running autonomous tasks) but open-source and self-hostable. It’s closest to OpenHands in architecture (sandbox-based execution) but broader in scope (not just coding — also research, content, any skill-based task).
The Sandbox Connection
DeerFlow’s sandbox is central. Every code execution happens in a Docker container. The agent gets a full Linux environment: shell, filesystem, network, Python, Node.js — whatever the task needs.
This is the same architectural principle behind OpenHands and the broader movement toward sandboxed agent execution. The agent generates code, the sandbox runs it safely, the output feeds back into the agent’s reasoning.
For agent infrastructure platforms like SandBase, DeerFlow represents a potential integration point: provide the sandbox-as-a-service that DeerFlow’s orchestrator calls for code execution, rather than requiring users to manage their own Docker infrastructure.
Part of the AI Agent Infrastructure Stack
DeerFlow is a framework-layer harness in the AI Agent Infrastructure Stack 2026. Related reading in the same cluster:
- LangChain and LangGraph — the orchestration framework you’d build a comparable harness on.
- Mastra — the TypeScript-first framework alternative.
FAQ
Is DeerFlow production-ready?
It’s actively used internally at ByteDance. The open-source version is functional but still evolving rapidly (2.0 was recent). Good for experimentation and internal tools; for customer-facing production, evaluate stability carefully.
What models does DeerFlow support?
Model-agnostic via OpenAI-compatible interface. Works with GPT-4o, Claude, Gemini, DeepSeek, Qwen, and any model accessible through a compatible API.
How does it compare to just using Claude Code for long tasks?
Claude Code is a coding agent — it writes and runs code. DeerFlow is a harness that orchestrates multiple capabilities: research, coding, content creation, file management. Claude Code could be one of DeerFlow’s sub-agents. They’re at different abstraction levels.
Can I add my own skills?
Yes. The skill system is extensible. Define a skill with its capabilities, register it, and the orchestrator can assign tasks to it.
Does it need a GPU?
No. DeerFlow is the orchestration layer — it calls LLM APIs remotely. It needs CPU/RAM for the sandbox (Docker) and orchestrator, but no GPU locally.
Key Takeaways
- DeerFlow is ByteDance’s open-source “SuperAgent harness” — a runtime for tasks that take minutes to hours, not seconds. It provides sandbox, memory, sub-agents, and skills out of the box.
- The “harness” concept is distinct from “framework”: you bring the agent logic, it brings the infrastructure. Less assembly, more immediate execution capability.
- Long-horizon tasks require architectural features (persistence, checkpointing, sub-agent coordination, memory management) that simple agent loops can’t provide.
- At 37K+ stars and #1 GitHub Trending, it represents growing demand for agents that do real work over extended timeframes, not just answer questions.
- The sandbox architecture connects directly to the broader agent infra trend: agents that execute code need isolation, and that isolation is becoming a standard infrastructure service.